Welcome to CHIMERA’s Documentation!
CHIMERA: An open source framework for combining multiple parcellations
Creating multi-source parcellations of the human brain is a fundamental task at several steps of the MRI analysis research workflow. Chimera facilitates this otherwise difficult operation with an intuitive and flexible interface for humans and machines, thereby assisting in the construction of sophisticated and more reliable processing pipelines. This repository contains the source code and atlases needed by Chimera.
📖 Documentation
Full documentation is available at: https://chimera-brainparcellation.readthedocs.io
The documentation includes:
Complete API reference
Installation guide
Usage examples
Parcellation methodology details
Parcellations fusion
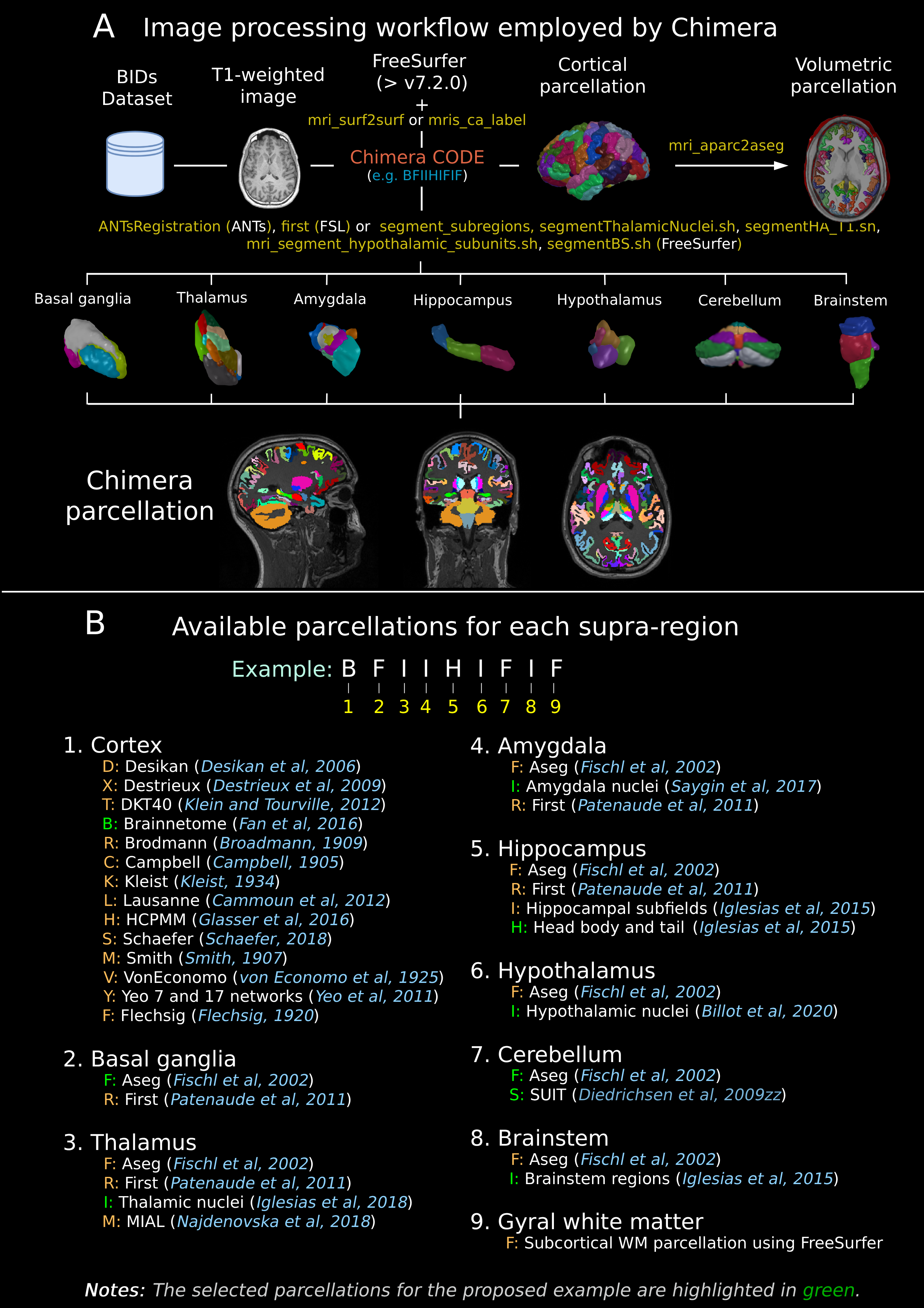
Chimera defines ten different supra-regions (cortex, subcortical structures, thalamus, amygdala, hippocampus, hypothalamus, cerebellum, brainstem, gyral white matter, and white-matter). Subcortical structures include only the regions that are not labeled as supra-regions. Subdivisions in each supra-region will be populated with the parcellation information of a single source. The available parcellation sources per supra-region, as well as one corresponding parcellation name, and a one-character unique identifier are configured in a JSON (JavaScript Object Notation) file.
Chimera code: A sequence of ten one-character identifiers (one per each supra-region) unambiguously denotes a single instance of combined parcellation (Figure 1B). Given the sequence of ten identifier characters, Chimera selects the atlas and/or applies the corresponding methodology to obtain the parcellation for each supra-region. These supra-region-specific parcellations are finally integrated to obtain the combined volumetric parcellation for each input subject, as well as its corresponding tab-separated values table of labels, region names, and rendering colors for visualization.
Chimera uses FreeSurfer to map cortical templates from fsaverage to individual space. It also applies different methods to obtain the hippocampal subfields and brainstem parcellations as well as the thalamic, amygdala and hypothalamic nuclei segmentations. FIRST and ANTs are also used for segmenting subcortical structures and thalamic nuclei respectively.
Requirements
Required Python Packages
Standard Library (Built-in, no installation required)
argparse - Command-line argument parsing
csv - CSV file reading and writing
datetime - Date and time handling
json - JSON encoder and decoder
operator - Standard operators as functions
os - Operating system interface
pathlib - Object-oriented filesystem paths
shutil - High-level file operations
subprocess - Subprocess management
sys - System-specific parameters and functions
time - Time access and conversions
typing - Support for type hints
Data Science & Analysis
Neuroimaging & Medical Data
nibabel - Access to neuroimaging file formats
pybids - BIDS (Brain Imaging Data Structure) toolkit
templateflow - Neuroimaging template management
CLI & User Interface
rich - Rich text and beautiful formatting for terminals
Specialized Tools
clabtoolkit - Connectomics Lab Toolkit
Installation
Install from PyPI (Recommended)
The easiest way to install CHIMERA is using pip:
# Create and activate a new conda environment
conda env create -f environment.yaml
conda activate chimera-env
pip install chimera-brainparcellation
This will automatically install all required dependencies including:
pandas
pybids
numpy
nibabel
rich
scipy
templateflow
clabtoolkit
Manual Installation
Alternatively, you can install all required external packages manually:
pip install pandas pybids numpy nibabel rich scipy templateflow clabtoolkit
Or using a requirements.txt file:
pip install -r requirements.txt
requirements.txt content:
pandas
pybids
numpy
nibabel
rich
scipy
templateflow
clabtoolkit
Required image processing packages:
Options
Brief description of input options:
Option |
Description |
|---|---|
|
List available parcellations for each supra-region. |
|
BIDs dataset folder. Different BIDs directories could be entered separating them by a comma. |
|
Derivatives folder. Different directories could be entered separating them by a comma. |
|
Sequence of ten one-character identifiers (one per each supra-region). |
|
FreeSurfer subjects dir. If the folder does not exist it will be created. |
|
Scale identification. This option should be supplied for multi-resolution cortical parcellations (e.g. Lausanne or Schaeffer). |
|
Segmentation identifier. |
|
Number of processes to run in parallel (default= Number of cores - 4). |
|
Grow of GM labels inside the white matter (mm). |
|
Subject IDs. Multiple subject ids can be specified separating them by a comma. |
|
Join cortical white matter and cortical gray matter regions. |
|
Overwrite the results. |
|
Verbose (0, 1 or 2). |
|
Help. |
Usage
General command line to use Chimera:
$ chimera -b <BIDs directory> -d <Derivatives directory> -p <Chimera code>
This command will run Chimera for all the subjects in the BIDs directory.
Simple examples
Running Chimera for 3 different parcellation codes (LFMFIIFIF,SFMFIIFIF,CFMFIIFIF). This will obtain the combined parcellations for all the T1-weighted images inside the BIDs dataset.
$ chimera -b <BIDs directory> -d <Derivatives directory> -p LFMFIIFIF,SFMFIIFIF,CFMFIIFI
Running Chimera for T1-weighted images included in a txt file:
$ chimera -b <BIDs directory> -d <Derivatives directory> -p LFMFIIFIF -ids <t1s.txt>
Example of t1s.txt file:
sub-00001_ses-0001_run-2
sub-00001_ses-0003_run-1
sub-00001_ses-post_acq-mprage
Cortical volumes will grow 0 and 2 mm respectively inside the white matter for the selected cortical parcellations.
$ chimera -b <BIDs directory> -d <Derivatives directory> -p LFMFIIFIF -g 0,2
Main files in the repository
chimera.py: Main python library for performing Chimera parcellations.
supraregions_dictionary.json: JSON file specifying the available parcellation sources per supra-region.
annot_atlases and gcs_atlases: Folder containing cortical atlases in .annot and .gcs file formats.
For detailed information about available parcellations for each supra-region, see the Parcellations and Methodologies page.
Results
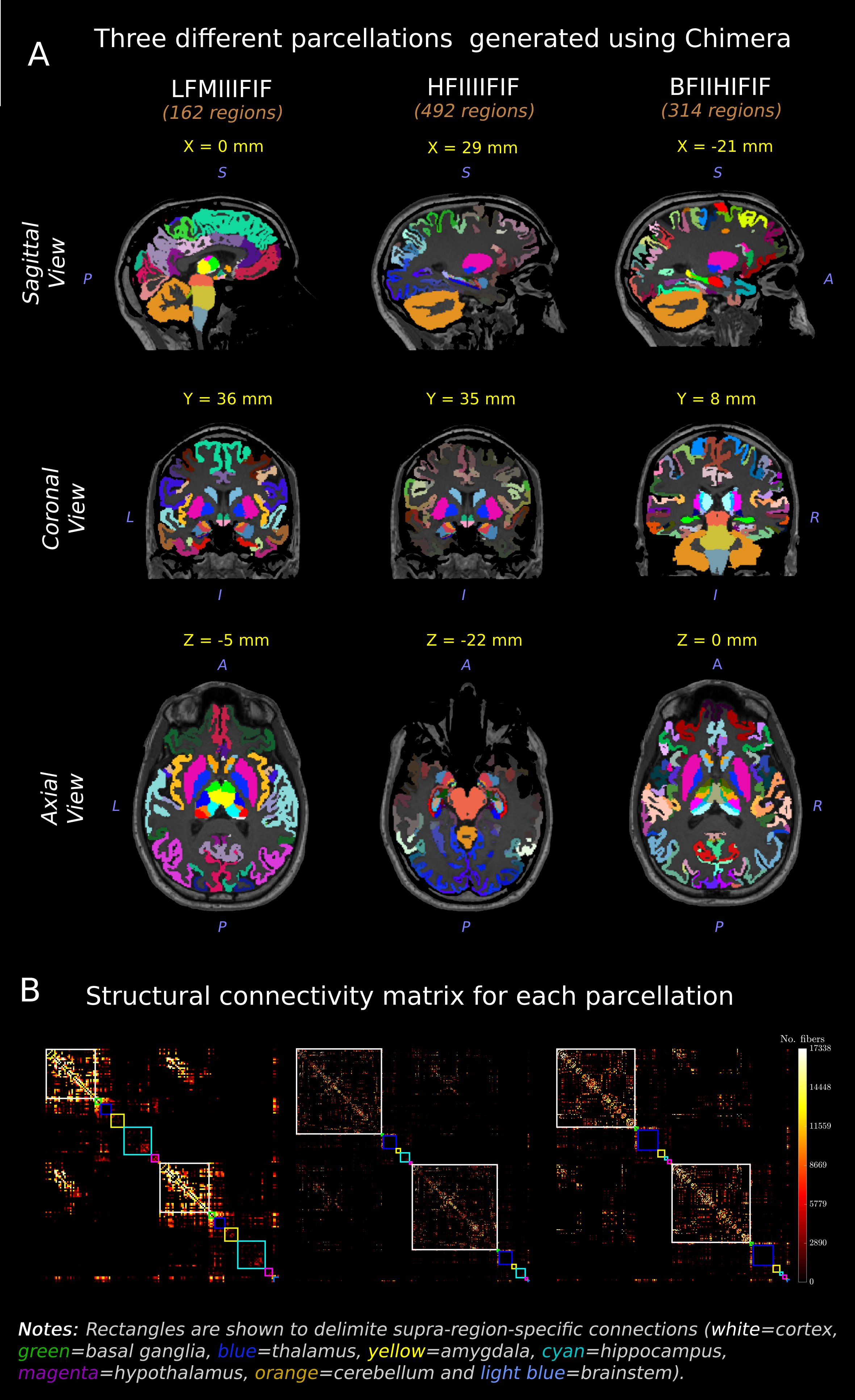
Chimera parcellations were generated using the following codes: LFMIIIFIF, HFIIIIFIF, BFIIHIFIF (162, 492 and 314 regions respectively). Figure 2A shows the corresponding results of the fused parcellations for a single subject. By filtering each individual’s tractogram with the corresponding Chimera parcellations, we generated connectivity matrices (Figure 2B).
License
User Guide
Getting Started: